Ein Projekt von Florian Schulz und Julian Stahnke
Buchstabensuppe
Buchstabensuppe lässt uns in die Geschichte der Worte eintauchen. Durch die Digitalisierung von über 5 Millionen Büchern können wir erahnen wann ein Wort zum ersten Mal schriftlich festgehalten wurde und wie sich dessen Gebrauch bis heute verändert hat – visualisiert in 360°.
Im Kurs Immersive Datenvisualisierung unter der Leitung von Prof. Boris Müller haben wir Buchstaben aufsteigen lassen. Sie schweben ungeordnet im Raum der 360°-Kuppel der Urania Potsdam. Sie schimmern, zeigen mal mehr, mal weniger ihrer plastischen Gestalt.
Auf der Suche nach sinnvoll arrangierten Zeichen ordnen die Zuschauer gedanklich das Chaos. Ein Räuspern, »Hallo?«. Die fünf Buchstaben des Wortes schwirren los. Sie formieren sich und reisen gemeinsam als Wort. Schnell wird klar: Die Kuppel kann uns hören und verstehen. Obendrein versorgt sie uns mit historischen Daten. Jedem Wort wird ein Graph zugeordnet, der darstellt wie häufig das Wort im Zeitraum von 1500–2008 gebraucht wurde. So entsteht in der Kuppel nach und nach ein Abbild der gesprochenen Worte bis sich ihre Bindung irgendwann auflöst.


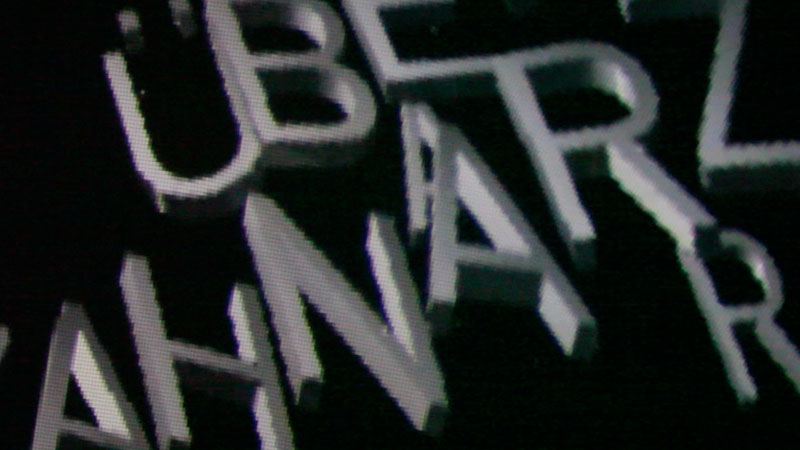
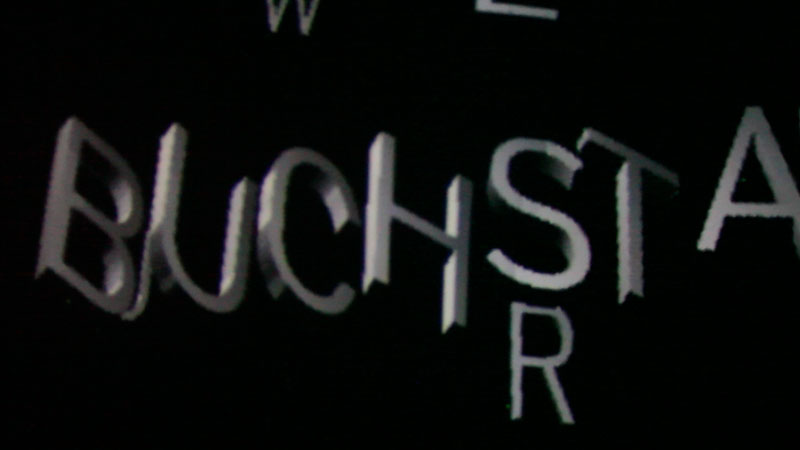


Fotos aus der Kuppel.
So funktioniert’s:
Programm
Die Installation wurde mit Processing programmiert. Das Programm besteht aus einem Partikelsystem, das Buchstaben entsprechend ihrer Häufigkeit in der deutschen Sprache im Raum verteilt. Graphen dienen zur Darstellung der zeitlichen Veränderung des Wortvorkommens.
Die Buchstaben wurden als Modelle aus Photoshop exportiert und in Processing geladen. Diese Methode war besser als der Ansatz, die Buchstaben selbst mit Geomerative zu erzeugen. Dank GLGraphics und GLModel konnten wir so mehrere Hundert Buchstaben im Raum darstellen. Die Reflexionen der Buchstaben sind das Ergebnis eines Cubemap-Shaders. Je nach Drehung wird also einfach ein anderer Teil eines texturierten Würfels reflektiert.
Die Graphen mussten speziell für die Verkrümmung der Kuppel berechnet werden, da wir aus Gründen der Performance nicht die komplette Szene zur Ausgabe verzerren konnten.
Daten
Google Ngram liefert 5 GB Daten zur Verwendung der Wörter. Für jedes Wort gibt es die entsprechenden Häufigkeiten für die Jahre in denen es Bücher gibt, die von Google gescannt wurden.
Spracherkennung
Die HTML5 Speech Input API ermöglicht es im Browser Google Chrome einem Eingabefeld die Möglichkeit der Spracherkennung zuzuweisen. Der Benutzer kann etwas sagen, was dann an Google gesendet wird. Nach der Analyse erhält der Browser die Transkription als Text. Dieses System haben wir genutzt um daraus die STT Library für Processing zu machen. Der Vorteil des Systems ist, dass es nicht auf eine bestimmte Person trainiert werden muss. Die Ergebnisse sind dafür außerordentlich genau. Der Nachteil ist, dass es eine Verzögerung von einigen Sekunden geben kann bis die Antwort zurückkommt.
Nachdem das Wort erkannt wurde, formieren sich die Buchstaben. Zeitgleich wird ein Graph aus den Daten von Google Ngram generiert.


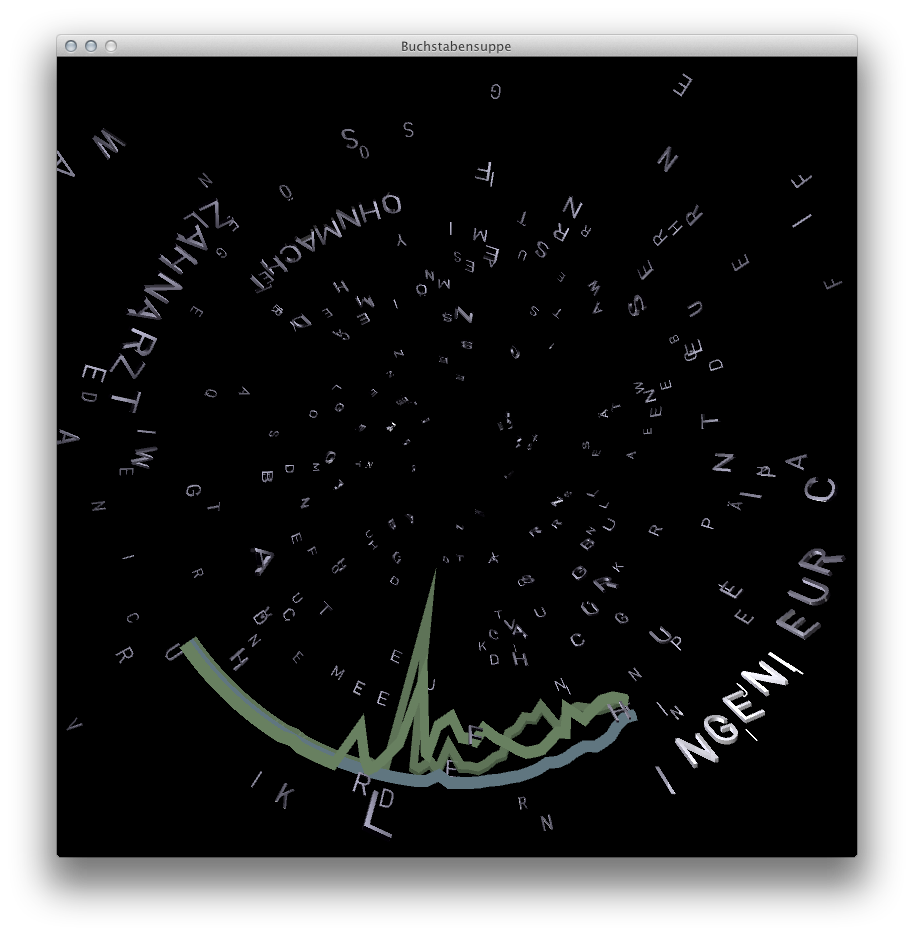
Screenshots der Processing-Anwendung.