Eine Doku von Florian Schulz und Julian Stahnke
Making–Of Buchstabensuppe
Da insbesondere während des Studiums der Weg das Ziel ist und Fehler viel interessanter sind als so manches Endergebnis (nicht umsonst ist Glitch-Art mittlerweile eine eigene Kunstrichtung): eine kleine Reise durch die Mülleimer unserer Festplatten.
Partikelsystem
Partikel und Buchstaben
Am Anfang entwickelten wir getrennt 3D-Buchstabenmodelle und ein Partikelsystem. Diese beiden Teile fügten wir dann nach einiger Zeit zusammen, wobei die Performance natürlich ein wenig in die Knie ging.

Verzweifelte Versuche, die Buchstaben mit geomerative in Processing zu rendern. Weder Qualität noch Performance waren den Photoshop-3D-Objekten gewachsen.
Ursprünglich überlegten wir, den Buchstaben Persönlichkeit zu geben. Sie sollten sich robbend, krabbelnd oder schwimmend durch die Kuppel bewegen. Wir haben die Buchstaben sogar hüpfen lassen! Dieser Ansatz wurde uns von Boris Müller jedoch sehr schnell ausgetrieben.
Das erste Partikelsystem mit 2D-Buchstaben.
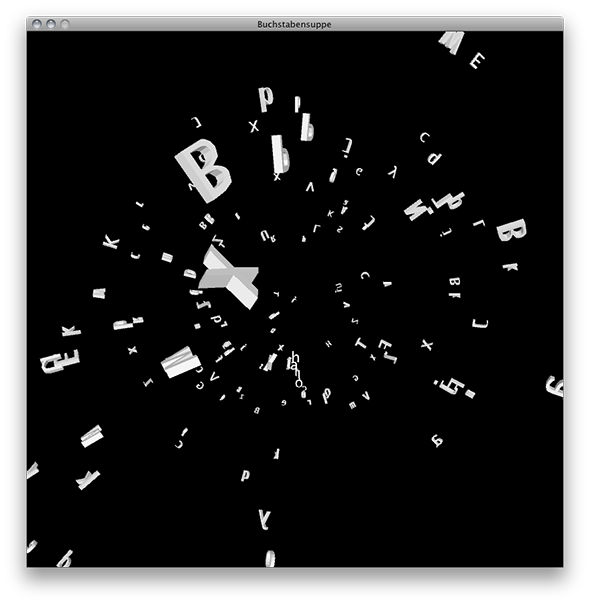


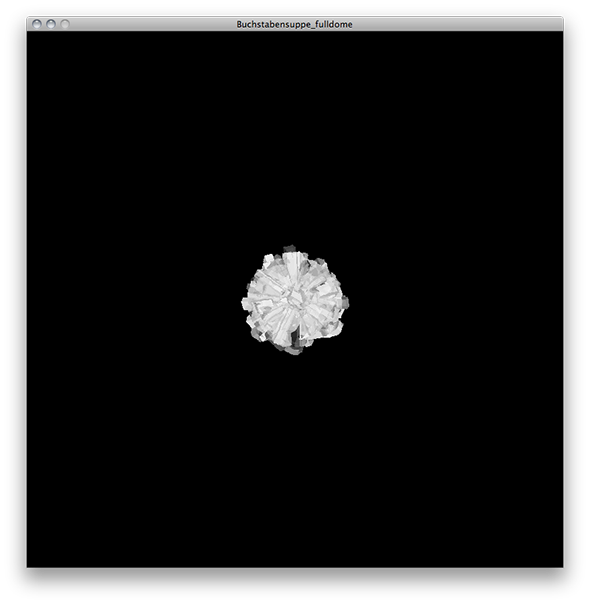
Partikelsystem mit 3D-Buchstaben, Screenshot in der virtuellen Kuppel, die Singularität.



Frühe Bewegungsstudien im Kuppelsimulator.
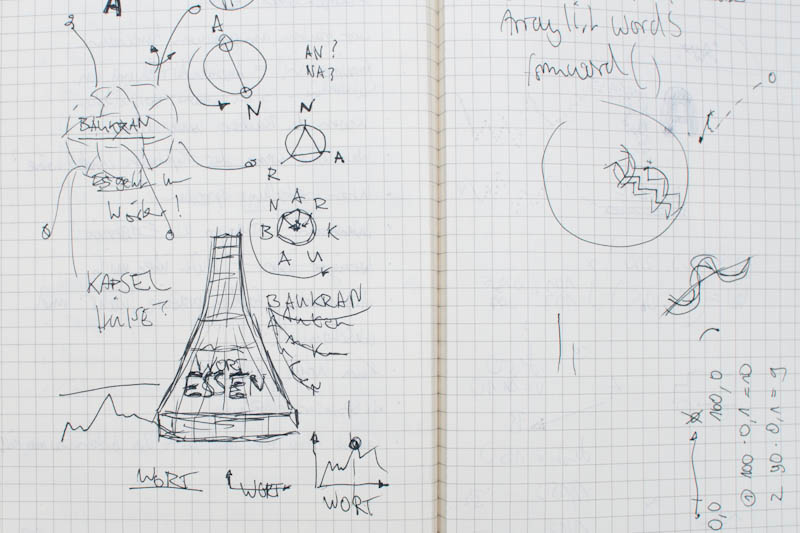

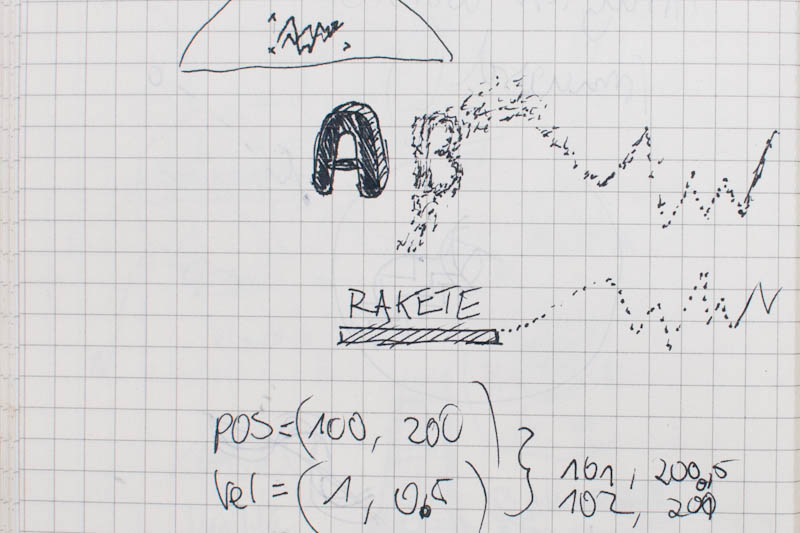
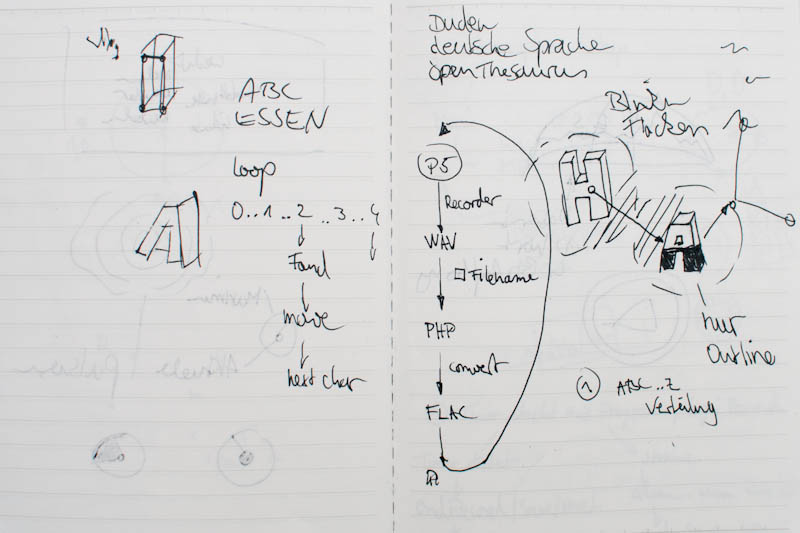
Skizzen zum Partikelsystem und der Logik hinter der Spracherkennung.
Shadern und Schämen
Irgendwann kamen wir auf die Idee, Shader zu benutzen. Mit Shadern kann man viele schöne Effekte erzeugen, wenn man sie geschickt einsetzt. Man kann aber auch einfach nur viele Effekte erzeugen.


Freie Shader-Experimente. Mal ausprobiert, was man so machen kann.



Die Begeisterung war groß: Bewegungsunschärfe in Echtzeit. Doch zu viel Dynamik ohne Grund. Am Ende blieb ein Cubemap-Shader, der für etwas Reflexionen und schönere Buchstaben sorgt.
Graphen
Das Problem
Ein einfaches Liniendiagramm zu zeichnen ist nicht schwer. Man setzt ein paar Punkte auf die x- und y-Achse – fertig. Wir brauchten jedoch ein gebogenes Liniendiagramm, dass sich der Kreisform der Kuppel anpassen würde. Nach kurzen Überlegen war auch das nicht sehr schwer; die y-Achse ist ein Vektor, der vom Kreismittelpunkt ausgeht und je nach Position auf der x-Achse rotiert wird.
So weit, so gut. Nun wollten wir allerdings ein 3D-Liniendiagramm. Unsere erste Idee war es, einfach dicke Linien zu nehmen. Die hatten aber keine Tiefe. Also vielleicht Röhren? Als wir nach stundenlangen Suchen immer noch keine Möglichkeit oder Library zum Röhrenzeichnen gefunden hatten, beschlossen wir, ein 3D-Liniendiagramm aus kastenförmigen Teilen zu zeichnen. Wie schwer konnte das schon sein?
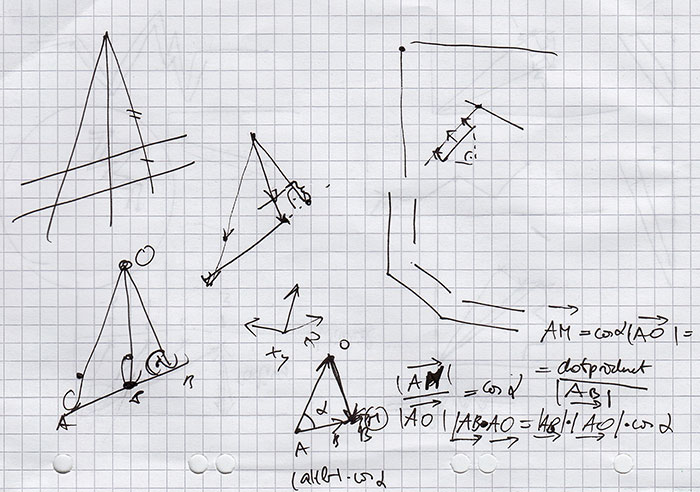
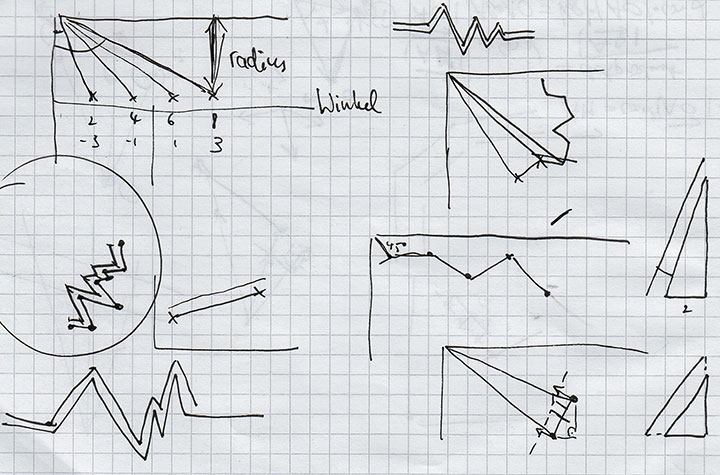
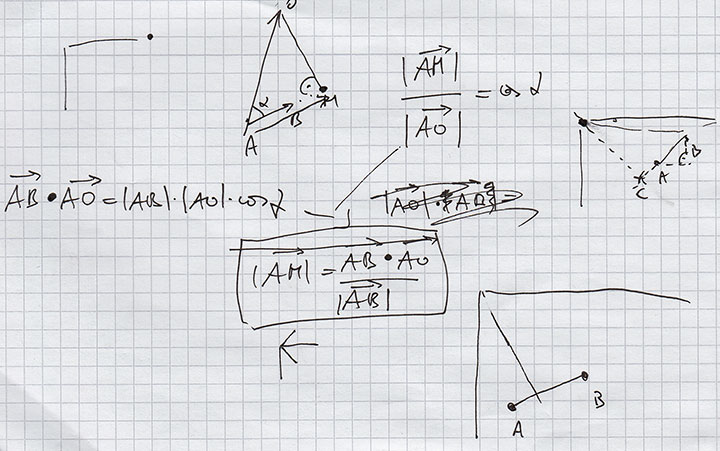
Skizzen und Formeln auf dem Weg zu den 3D-Graphen.
Die Lösung
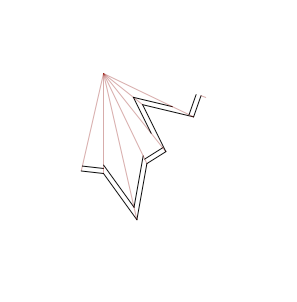
Es funktioniert! In einer Nachtschicht wurden die Linien dazu überredet, sich ordentlich anzuordnen. Es gab sogar zwei verschiedene Ansätze: einen mathematisch-geometrisch-eleganten und einen eher pragmatischen. Für welchen wir uns entschieden haben, kann man im Quelltext sehen.
Die Spracherkennung
Es gibt ein paar Programme und Libraries, die Spracherkennung ermöglichen. Meistens ist das dann aber auf Englisch beschränkt und es gibt so gut wie nichts, was einen freien Wortschatz akzeptiert. Die meisten System benötigen eine Grammatik, also Kommandos auf die sie reagieren. Da das für unsere Idee nicht genug war, kam Google zur Hilfe. Der Browser Google Chrome bietet bereits Spracherkennung als HTML5-Element für Eingabefelder an. Da es allerdings keine offizielle API für die Spracherkennung gibt, mussten wir einige Umwege nehmen. Die Sprache musste manuell aufgezeichnet und encodiert werden, als POST-Request an Google geschickt und das JSON ausgewertet werden. Das war so komplex, dass daraus eine einfache Library für Processing wurde.
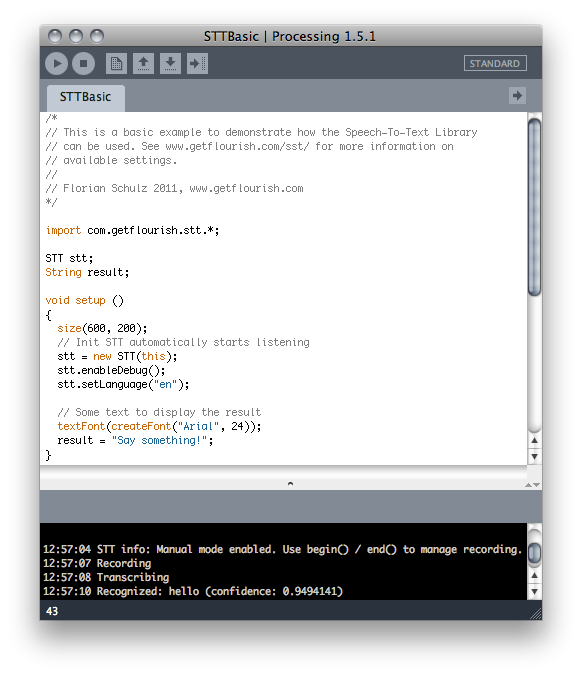
Die STT-Library.